Hello! I am currently the Chief Technology Officer and Chief Scientist at Molecule.one, a leading startup in the AI for chemistry space that combines in a closed loop high-throughput organic chemistry laboratory with machine learning models. Our main goal is to speed up drug discovery by making synthesis more predictable. I am passionate about improving fundamental aspects of deep learning and how it can be used to empower scientific discovery. I am also a Venture Advisor at Expeditions Fund where I help select AI startups for investment.
If you are looking for an advisor for your startup or PhD advisor, please feel free to reach out!
In 2024, I am teaching Automated Scientific Discovery using Deep Learning course at Jagiellonian University.
In my scientific work, I have largely focused on the role of optimization in the success of deep learning. My main contribution is largely resolving the mystery why learning rate, a fundamental hyperparameter, impacts generalization in deep learning. In the process we have discovered that all deep learning trainings go through chaotic phase in the beginning of training. This in particular has been part of Understanding Deep Learning book (Prince, MIT press). For more details see our ICLR 2020 paper (spotlight). This is closely related to the Edge of Stability phenomenon.
I completed a post-doc with Kyunghyun Cho and Krzysztof Geras at New York University, and was also an an Assistant Professor at Jagiellonian University (member of GMUM.net). I received my PhD from Jagiellonian University co-supervised by Jacek Tabor and Amos Storkey (University of Edinburgh). During PhD, I closely collaborated as a visiting researcher with Yoshua Bengio, and with Google Research in Zurich.
I do my best to contribute to the broad machine learning community. Currently, I serve as an Action Editor for TMLR and an area chair for ICLR 2023 (before that NeurIPS 2020-23, ICML 2020-22, ICLR 2020-22).
My email is staszek.jastrzebski (on gmail).
News
Current students
- [PhD] Łukasz Maziarka (UJ), co-advised with Jacek Tabor
- [PhD] Mateusz Pyla (UJ & IDEAS), co-advised with Tomasz Trzciński
Previous students
- [MSc] Piotr Helm (UJ)
- [MSc] Bartosz Krzepkowski (UW)
- [MSc] Przemysław Kaleta (PW) - Speeding-up retrosynthesis, co-advised with Piotr Miłoś
- [MSc] Aleksandra Talar (UJ) - Out-of-distribution generalization in molecule property prediction
- [PhD] Maciej Szymczak (UJ), co-advised with Jacek Tabor
- [MSc] Sławomir Mucha (UJ) - Pretraining in deep learning in cheminformatics
- [MSc] Tobiasz Ciepliński (UJ) - Evaluating generative models in chemistry using docking simulators
- [BSc] Michał Zmysłowski (UW) - Is noisy quadratic model of training of deep neural networks realistic enough?
- [MSc] Olivier Astrand (NYU) - Memorization in deep learning
- [MSc] Tomasz Wesołowski (UJ) - Relevance of enriching word embeddings in modern deep natural language processing
- [MSc] Andrii Krutsylo (UJ) - Physics aware representation for drug discovery
- [BSc] Michał Soboszek (UJ) - Evaluating word embeddings
- [MSc] Jakub Chłędowski (UJ) - Representation learning for textual entailment
- [MSc] Mikołaj Sacha (UJ) - Meta learning and sharpness of the minima
Selected Publications
For a full list please see my Google Scholar profile.
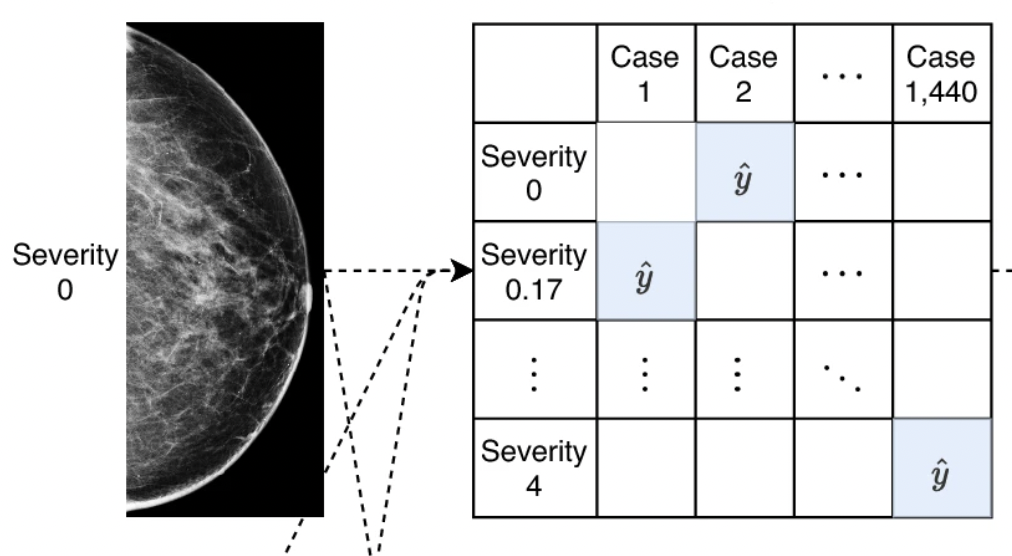
Differences between human and machine perception in medical diagnosis
T. Makino, S. Jastrzebski, Witold Oleszkiewicz, [...], Kyunghyun Cho, Krzysztof J Geras
Nature Scientific Reports 2022
paper
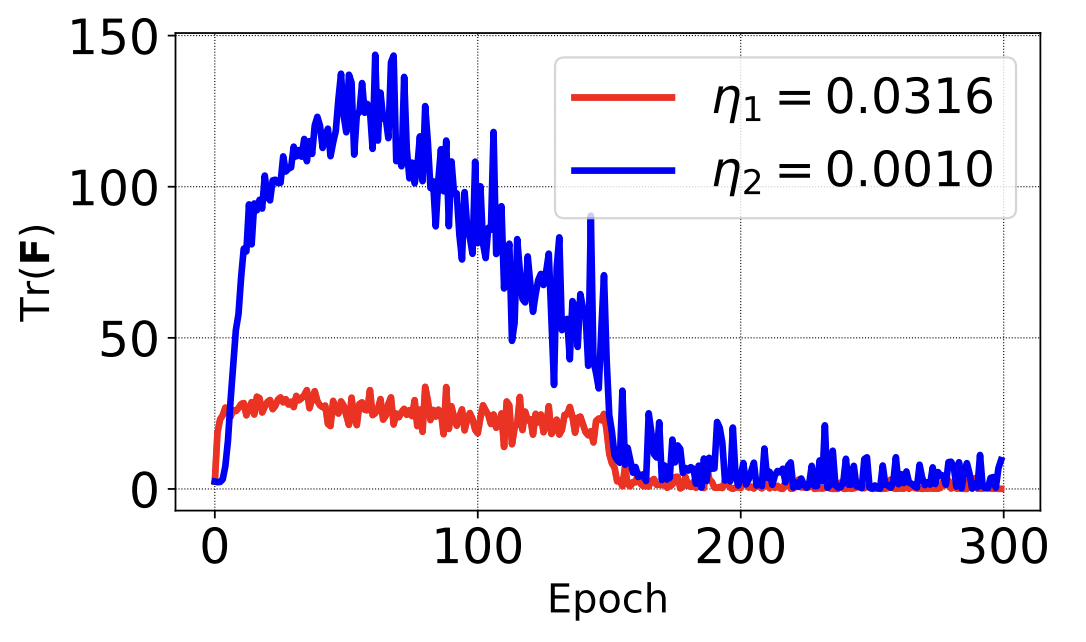
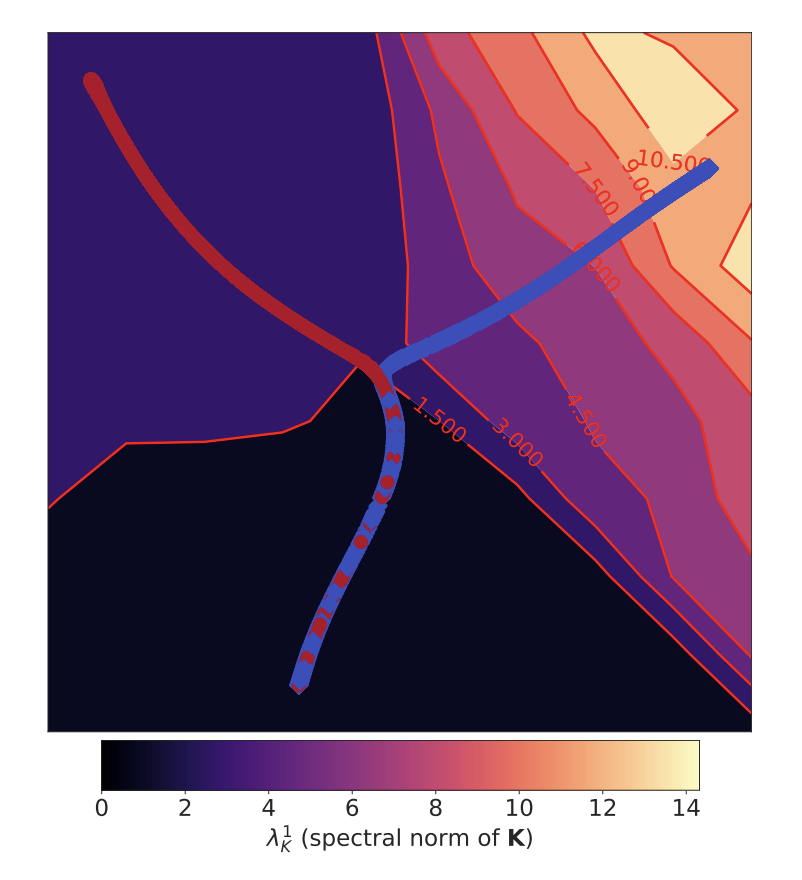
Catastrophic Fisher Explosion: Early Phase Fisher Matrix Impacts Generalization
S. Jastrzebski, D. Arpit, O. Astrand, G. Kerg, H. Wang, C. Xiong, R. Socher, K. Cho*, K. Geras*
International Conference on Machine Learning 2021
paper
talk
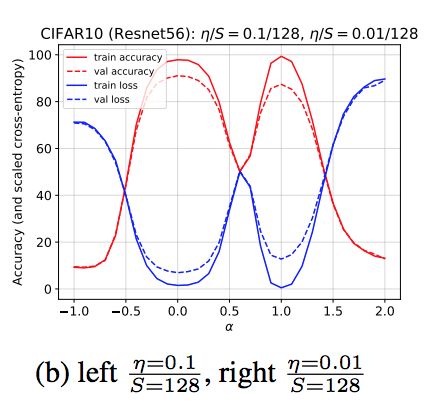
The Break-Even Point on the Optimization Trajectories of Deep Neural Networks
S. Jastrzębski, M. Szymczak, S. Fort, D. Arpit, J. Tabor, K. Cho*, K. Geras*
International Conference On Learning Algorithms 2020 (Spotlight)
paper
talk
Three Factors Influencing Minima in SGD
S. Jastrzębski*, Z. Kenton*, D. Arpit, N. Ballas, A. Fischer, Y. Bengio, A. Storkey
International Conference on Artificial Neural Networks 2018 (oral), International Conference on Learning Representations 2018 (workshop)
paper
A Closer Look at Memorization in Deep Networks
D. Arpit*, S. Jastrzębski*, N. Ballas*, D. Krueger*, T. Maharaj, E. Bengio, A. Fischer, A. Courville, S. Lacoste-Julien, Y. Bengio
International Conference on Machine Learning 2017
paper
poster
slides